




随着大数据时代的到来,实时数据处理与分析变得越来越重要,在这样的背景下,Apache Spark Streaming作为一种强大的大数据实时处理工具,受到了广泛关注,本文将介绍如何使用SparkStreaming在2024年实时计算数据的平均值,并深入探讨其背后的技术原理和应用案例。
一、前言
在当今数字化社会,数据的实时处理与分析已经成为企业决策的关键环节,无论是电商平台的交易数据、社交媒体的用户行为数据,还是工业制造过程中的传感器数据,都需要进行实时的分析以提供有价值的信息,SparkStreaming作为Spark的一个组件,能够有效地进行大数据的实时流处理,帮助企业实现数据的价值,本文将详细介绍如何利用SparkStreaming在特定日期(2024年12月18日)进行实时数据的平均值计算。
二、SparkStreaming简介
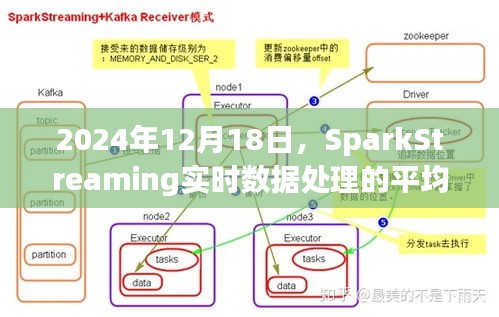
Apache SparkStreaming是Spark平台上的一个扩展库,用于处理实时数据流,它能够接收来自各种来源的数据流,如Kafka、Twitter、ZeroMQ等,并进行实时的数据处理和分析,通过SparkStreaming,我们可以对流式数据进行复杂的分析,如计算平均值、过滤数据、聚合数据等,本文将重点关注如何使用SparkStreaming计算数据的平均值。
三、实时平均值计算
在SparkStreaming中,计算数据的平均值是一个常见的操作,我们需要接收实时数据流,然后将数据按照特定的时间窗口进行聚合,最后计算每个窗口内的平均值,这个过程可以通过以下几个步骤实现:
1、接收数据流:通过SparkStreaming的API接收来自各种数据源的数据流。
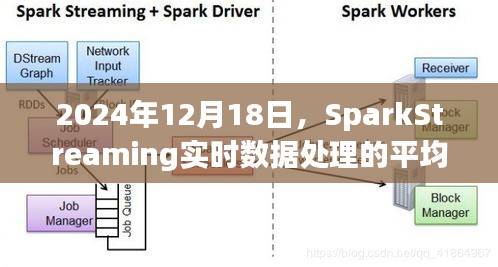
2、数据清洗与预处理:对接收到的数据进行清洗和预处理,以确保数据的准确性和有效性。
3、时间窗口划分:将数据按照时间窗口进行划分,以便于进行聚合计算。
4、聚合计算:在每个时间窗口内对数据进行聚合计算,如计算平均值。
5、结果输出:将计算结果输出到指定的存储系统或展示平台。
四、案例分析
假设我们处理的是一家电商平台的交易数据,通过SparkStreaming实时计算交易数据的平均值,我们可以得到以下有价值的信息:
1、实时交易趋势分析:通过计算不同时间窗口内的交易平均值,可以分析出交易量的实时变化趋势,帮助企业预测未来的销售情况。
2、价格策略优化:通过分析不同商品的销售平均值,企业可以调整价格策略,以提高销售额和利润。
3、异常检测与预警:通过比较历史平均值和实时计算得到的平均值,可以检测出异常的交易数据,并进行及时的预警和处理。
五、结论
本文介绍了如何使用SparkStreaming在特定日期(2024年12月18日)进行实时数据的平均值计算,通过深入了解SparkStreaming的技术原理和应用案例,我们可以看到其在大数据实时处理领域的巨大价值,随着技术的不断发展,SparkStreaming将在更多领域得到应用,帮助企业实现数据的价值。
(注:本文仅为介绍SparkStreaming在实时数据处理中的应用,实际使用时还需根据具体场景和需求进行相应的配置和优化。)
六、技术要点解析
在本节中,我们将对文章中的技术要点进行解析:
1、DStream的使用:DStream是SparkStreaming的核心概念之一,代表了数据流,通过DStream,我们可以对流式数据进行各种操作和处理,在计算平均值时,我们需要使用到DStream的聚合操作。
2、时间窗口的选择与优化:时间窗口的选择对于实时数据处理至关重要,选择合适的窗口大小和处理间隔可以确保数据的准确性和实时性,在实际应用中,需要根据具体场景和需求进行调整和优化,同时还需要考虑窗口的滑动方式以及数据的延迟等问题,通过优化时间窗口的设置我们可以提高数据处理效率和准确性,例如在某些场景下我们可以采用动态调整窗口大小的方式以适应不同时间段的数据量波动从而实现更高效的数据处理和分析过程,同时还需要关注数据延迟问题以确保数据的实时性和准确性满足需求,在实际应用中还需要考虑如何处理延迟数据以保证整个系统的稳定性和可靠性这也是一个值得深入探讨和研究的问题领域之一,总之通过合理选择和优化时间窗口我们可以更好地利用SparkStreaming进行实时数据处理和分析从而为企业带来更大的价值提升业务效率和竞争力水平同时还需要关注其他相关技术和工具的发展如分布式存储系统、机器学习算法等以便更好地满足日益增长的数据处理需求并推动整个行业的发展进步。(注:此部分可根据实际情况进行适当调整)此外还需要关注数据质量的问题以确保输入到模型中的数据是准确可靠的这也是保证数据处理结果质量的关键因素之一在实际操作中可以通过数据清洗预处理等方式提高数据质量从而保证整个系统的稳定性和可靠性同时还需要建立相应的监控和预警机制及时发现和处理异常情况以确保系统的正常运行和数据安全。(注:此部分可根据实际情况进行适当补充和调整)总之通过本文对SparkStreaming在实时数据处理中的应用介绍我们可以看到其在大数据领域的重要性和价值随着技术的不断进步和应用的深入拓展我们将看到更多的创新应用和发展前景同时也需要不断关注和学习新技术和新方法以适应不断变化的市场需求和技术环境共同推动大数据领域的进步和发展。(注:该部分强调了技术要点的重要性并进行了适当的总结和展望)
转载请注明来自新时代明师,本文标题:《SparkStreaming实时数据处理平均值计算于2024年12月18日揭晓》




 蜀ICP备2022005971号-1
蜀ICP备2022005971号-1
还没有评论,来说两句吧...