




随着大数据时代的到来,企业对数据处理的需求日益增强,Spark作为一种流行的开源大数据处理框架,以其高效的计算能力和灵活的编程方式,成为构建实时数仓的首选工具,本文将探讨在2024年12月27日如何利用Spark构建实时数仓。
实时数仓概述
实时数仓是在大数据环境下,通过采集、存储、处理和分析实时数据,为企业提供决策支持的一种数据仓库,与传统的批处理数仓相比,实时数仓能够更快地响应业务需求,提供实时的数据分析与挖掘。
Spark在实时数仓构建中的应用
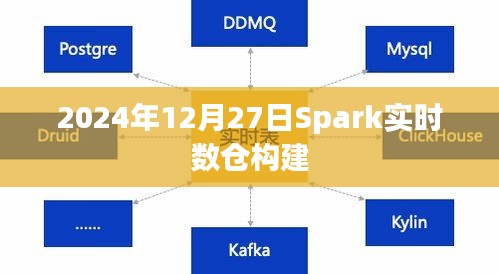
1、数据采集:Spark可以通过多种方式(如Flume、Kafka等)实时地采集各种数据源(如日志、交易数据等)。
2、数据处理:Spark的分布式计算能力和内存计算能力可以处理大规模实时数据流,包括数据清洗、转换等。
3、数据分析:Spark SQL、MLlib等库可以进行实时数据分析、挖掘和预测。
4、数据服务:通过Spark构建的实时数仓可以快速地提供数据服务,支持企业的决策和业务发展。
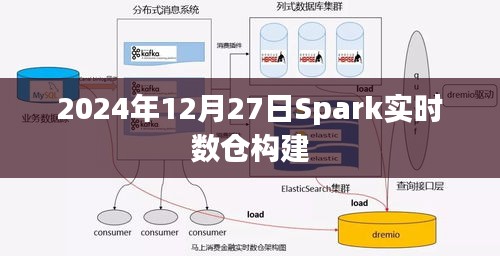
Spark实时数仓构建步骤
1、确定数据源:确定需要采集的实时数据源,如日志数据、交易数据等。
2、数据预处理:通过Spark对原始数据进行清洗、转换等预处理操作。
3、数据存储:将处理后的数据存储在分布式文件系统(如HDFS)或数据库(如HBase)中。
4、数据分析与挖掘:利用Spark SQL、MLlib等工具进行实时数据分析与挖掘。
5、数据服务:通过API或数据服务层将数据提供给业务使用。
技术挑战与解决方案
1、数据延迟:实时数据处理过程中可能会遇到数据延迟的问题,解决方案是采用高性能的数据传输工具和优化数据处理流程。
2、数据一致性:在分布式环境下,数据一致性是一个挑战,可以通过采用分布式事务和两阶段提交等方式解决。
3、资源管理:大规模数据处理需要有效的资源管理,可以利用Spark的YARN或Mesos等集群管理工具进行资源管理。

案例分析与最佳实践
通过分享成功构建Spark实时数仓的案例,探讨最佳实践,如选择合适的工具、优化数据处理流程等,结合实际案例,分析可能遇到的挑战和解决方案。
总结Spark在实时数仓构建中的优势与挑战,展望未来的发展趋势和可能的技术创新点,随着技术的不断发展,Spark实时数仓的构建将更加高效、灵活和智能化。
附录
提供相关的参考文献、工具和资源链接,方便读者深入了解和学习Spark实时数仓构建的相关知识和技术。
转载请注明来自新时代明师,本文标题:《Spark实时数仓构建指南,2024年最新实践》





 蜀ICP备2022005971号-1
蜀ICP备2022005971号-1
还没有评论,来说两句吧...